從基礎(chǔ)軟件服務(wù)入手,高效學(xué)習(xí)大數(shù)據(jù)
在當(dāng)今數(shù)據(jù)驅(qū)動的時代,大數(shù)據(jù)技術(shù)已成為企業(yè)和個人發(fā)展的重要支柱。對于初學(xué)者而言,面對龐雜的技術(shù)棧和概念,往往感到無從下手。實際上,從基礎(chǔ)軟件服務(wù)切入,是掌握大數(shù)據(jù)技能的一條高效路徑。本文將分步驟介紹如何通過基礎(chǔ)軟件服務(wù)來學(xué)習(xí)和實踐大數(shù)據(jù)技術(shù)。
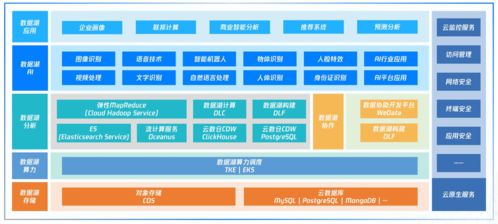
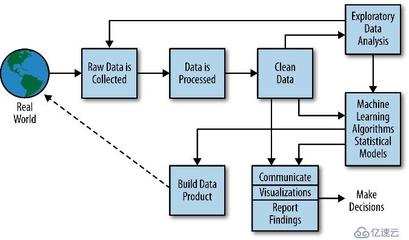
理解大數(shù)據(jù)的基礎(chǔ)架構(gòu)至關(guān)重要。大數(shù)據(jù)生態(tài)系統(tǒng)通常包括數(shù)據(jù)采集、存儲、處理、分析和可視化等環(huán)節(jié)。作為起點,您應(yīng)熟悉核心組件,如Hadoop和Spark,它們是處理海量數(shù)據(jù)的基石。Hadoop的HDFS提供分布式存儲,而MapReduce或Spark則負(fù)責(zé)分布式計算。建議從官方文檔和在線教程開始,了解這些工具的基本原理和部署方法。
注重實踐環(huán)境的搭建。選擇一款適合初學(xué)者的基礎(chǔ)軟件服務(wù),例如使用Apache Hadoop的發(fā)行版(如Cloudera或Hortonworks),它們提供了集成的管理界面,簡化了安裝和配置過程。您可以在本地虛擬機或云平臺(如AWS、阿里云)上部署這些服務(wù),通過動手操作加深理解。記住,實踐是學(xué)習(xí)大數(shù)據(jù)的關(guān)鍵:嘗試上傳數(shù)據(jù)集、運行簡單的MapReduce作業(yè)或Spark任務(wù),觀察數(shù)據(jù)流動和處理結(jié)果。
然后,擴展您的知識面到相關(guān)軟件服務(wù)。大數(shù)據(jù)不僅涉及處理框架,還包括數(shù)據(jù)庫(如HBase、Cassandra)、消息隊列(如Kafka)和數(shù)據(jù)集成工具(如Sqoop、Flume)。這些基礎(chǔ)服務(wù)協(xié)同工作,構(gòu)建完整的數(shù)據(jù)管道。例如,使用Kafka進(jìn)行實時數(shù)據(jù)流處理,再結(jié)合Spark Streaming進(jìn)行分析。推薦通過項目驅(qū)動學(xué)習(xí):設(shè)計一個小型應(yīng)用,如日志分析系統(tǒng),從數(shù)據(jù)采集到可視化全流程實踐,這能幫助您融會貫通。
關(guān)注學(xué)習(xí)資源和社區(qū)支持。大數(shù)據(jù)領(lǐng)域更新迅速,保持學(xué)習(xí)動力至關(guān)重要。利用在線課程(如Coursera、edX上的大數(shù)據(jù)專項)、官方文檔和開源社區(qū)(如Apache項目論壇)獲取最新信息。參與實際項目或貢獻(xiàn)代碼,可以提升解決實際問題的能力。同時,學(xué)習(xí)基礎(chǔ)軟件服務(wù)的監(jiān)控和優(yōu)化技巧,例如使用Ambari管理Hadoop集群,確保系統(tǒng)高效運行。
培養(yǎng)數(shù)據(jù)思維和持續(xù)學(xué)習(xí)的習(xí)慣。大數(shù)據(jù)技術(shù)是工具,真正的價值在于如何用它解決業(yè)務(wù)問題。從基礎(chǔ)軟件服務(wù)出發(fā),逐步構(gòu)建知識體系,結(jié)合統(tǒng)計學(xué)和機器學(xué)習(xí)基礎(chǔ),您將能從容應(yīng)對復(fù)雜的數(shù)據(jù)挑戰(zhàn)。記住,學(xué)習(xí)大數(shù)據(jù)沒有捷徑,但通過循序漸進(jìn)地掌握基礎(chǔ)服務(wù),您將打下堅實的基礎(chǔ),并在數(shù)據(jù)世界中游刃有余。
如若轉(zhuǎn)載,請注明出處:http://www.hbagnk.com/product/2.html
更新時間:2026-05-30 21:21:31